Pytorch中的张量
定义
张量(tensor)是一组具有多维度结构的数。维度的个数称为 阶(rank),通过tensor.dim()查看。张量的具体形状通过tensor.shape()查看。
索引方式
切片索引
像 python 的 list 和 numpy 的 array 一样,张量可以使用 start:stop 或 start:stop:step 这样的语法进行切片。stop 是不被包括在内的第一个元素。
a = torch.tensor([0, 11, 22, 33, 44, 55, 66])
print(0, a) # (0) Original tensor
print(1, a[2:5]) # (1) Elements between index 2 and 5
print(2, a[2:]) # (2) Elements after index 2
print(3, a[:5]) # (3) Elements before index 5
print(4, a[:]) # (4) All elements
print(5, a[1:5:2]) # (5) Every second element between indices 1 and 5
print(6, a[:-1]) # (6) All but the last element
print(7, a[-4::2]) # (7) Every second element, starting from the fourth-last访问张量中的单行或单列有两种常见方法:
- 使用一个整数索引会使张量的阶(rank)减少 1。
- 使用一个长度为 1 的切片(slice)则保持张量的阶不变。
a = torch.tensor([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
row_r1 = a[1, :] # Rank 1 view of the second row of a tensor([5, 6, 7, 8]) torch.Size([4])
row_r2 = a[1:2, :] # Rank 2 view of the second row of a tensor([[5, 6, 7, 8]]) torch.Size([1, 4])整数张量索引
整数索引可以互换张量行和列的顺序。
a = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# Create a new tensor of shape (5, 4) by reordering rows from a:
# - First two rows same as the first row of a
# - Third row is the same as the last row of a
# - Fourth and fifth rows are the same as the second row from a
idx = [0, 0, 2, 1, 1] # index arrays can be Python lists of integers
print(a[idx])
# Create a new tensor of shape (3, 4) by reversing the columns from a
idx = torch.tensor([3, 2, 1, 0]) # Index arrays can be int64 torch tensors
print(a[:, idx])更一般地说,给定两个索引数组 idx0 和 idx1,它们各自有 N 个元素,那么表达式 a[idx0, idx1] 等价于:
torch.tensor([
a[idx0[0], idx1[0]],
a[idx0[1], idx1[1]],
...,
a[idx0[N - 1], idx1[N - 1]]
])布尔张量索引
布尔张量索引允许你根据一个布尔掩码(boolean mask)选取张量中任意的元素。
a = torch.tensor([[1,2], [3, 4], [5, 6]])
# Find the elements of a that are bigger than 3. The mask has the same shape as
# a, where each element of mask tells whether the corresponding element of a
# is greater than three.
mask = (a > 3)
# We can use the mask to construct a rank-1 tensor containing the elements of a
# that are selected by the mask
print(a[mask])
# We can also use boolean masks to modify tensors; for example this sets all
# elements <= 3 to zero:
a[a <= 3] = 0
print(a)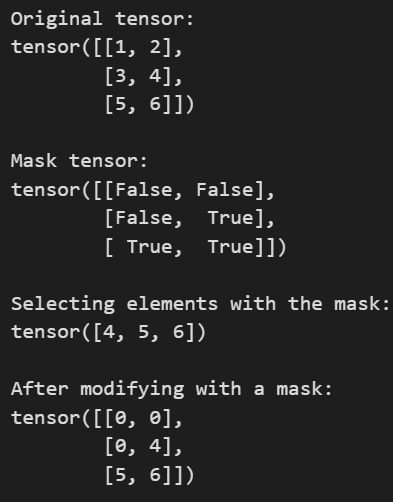
张量操作
按元素操作
基本的数学函数在张量上是按元素(elementwise)操作的,可以通过运算符重载,torch 模块中的函数,以及张量对象的方法来使用。
x = torch.tensor([[1, 2, 3, 4]], dtype=torch.float32)
y = torch.tensor([[5, 6, 7, 8]], dtype=torch.float32)
# Elementwise sum; all give the same result
print('Elementwise sum:')
print(x + y)
print(torch.add(x, y))
print(x.add(y))
x = torch.tensor([[1, 2, 3, 4]], dtype=torch.float32)
print(torch.sqrt(x))
print(x.sqrt())
print(torch.sin(x))
print(x.sin())
print(torch.cos(x))
print(x.cos())reduction 操作
我们有时希望对张量的部分或全部元素执行聚合操作,比如求和,这类操作被称为 reduction 操作。reduction 操作包括求和(sum)、求平均值(mean)、取最小值(min)、取最大值(max)等。
reduction 操作降低张量的阶。传入参数 dim=d 后,输入张量中索引为 d 的维度会从输出张量的形状中移除。如果传入参数 keepdim=True,则指定的维度不会被移除而是变为 1。在进行 reduction 操作时,考虑张量的形状比较便于理解。
有的 reduction 操作返回不止一个值,比如 min 会返回指定维度上的最小值,以及最小值所在的位置索引:
# 创建一个张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
lresult = x.min(dim=1)
# result是一个命名元组,有两个属性:
print(result.values) # 获取最小值
print(result.indices) # 获取最小值的索引位置
# 或者解包
col_min_vals, col_min_idxs = x.min(dim=0)以上的torch.min输入的参数一般是一个张量。有另一个函数torch.minimum用于按元素比较两个 tensor,返回对应元素中较小的那个。类似的还有torch.maximum。
import torch
a = torch.tensor([1, 4, 3])
b = torch.tensor([2, 2, 5])
torch.minimum(a, b)
# 输出: tensor([1, 2, 3])
Reshaping 操作
view
PyTorch 提供了多种操作张量形状的方法。比如view()返回一个与输入具有相同元素数量,但形状不同的新张量。
view() 按照原张量的行优先顺序来重新排列元素,而张量在内存中存储也是行优先的。
正如其名称所暗示,通过view()返回的张量与输入共享相同的数据,因此对其中一个的更改将影响另一个。
我们可以使用view()将矩阵展平为向量,将一维向量转换为二维的行矩阵或列矩阵。
unsqueeze
unsqueeze在指定位置插入一个维度,它有一种简便写法。a[:, None]的意思是在原张量的后面新增一个维度。
c = torch.tensor([1, 2, 3])
# 方式1:用 None
a = c[:, None]
print(a.shape) # torch.Size([3, 1])
# 方式2:用 unsqueeze
b = c.unsqueeze(1)
print(b.shape) # torch.Size([3, 1])cat 与 stack
torch.cat 沿现有的维度拼接张量,不会增加新的维度。
如果你有两个形状为 (2, 3) 的张量,使用 torch.cat 沿着第 0 维(行)拼接后,结果张量的形状将是 (4, 3)
torch.stack 沿一个新的维度堆叠张量,会增加一个新的维度。
如果你有两个形状为 (2, 3) 的张量,使用 torch.stack 沿新的第 0 维堆叠结果张量的形状将是 (2, 2, 3)
张量与标量的计算
张量和标量(Scalar)可以直接进行运算,而且操作是元素级(element-wise)的,PyTorch 会自动广播标量到张量的每个元素。比如+、-、*、/、==。
import torch
tensor = torch.tensor([1.0, 2.0, 3.0])
scalar = 2.0
# 加法
result_add = tensor + scalar # 每个元素加2
print(result_add) # tensor([3., 4., 5.])
# 乘法
result_mul = tensor * scalar # 每个元素乘2
print(result_mul) # tensor([2., 4., 6.])
# 减法
result_sub = tensor - scalar
print(result_sub) # tensor([-1., 0., 1.])
# 除法
result_div = tensor / scalar
print(result_div) # tensor([0.5, 1.0, 1.5])
# 比较
result = tensor == scalar
print(result) # tensor([False, True, False])
广播
广播(Broadcasting)是一种强大的机制,它允许 PyTorch 在执行算术运算时处理形状不同的数组。
将两个张量进行广播(broadcasting)时,遵循以下规则:
如果两个张量的阶(rank)不同,先在较低阶张量的形状(shape)前面补 1,直到两个形状长度相同。
如果在某个维度上,两者的大小相同,或者其中一个张量在该维度上的大小为 1,那么这两个张量在这个维度上被认为是兼容的。
只有当两个张量在所有维度上都兼容时,它们才能进行广播。
广播之后,每个张量的形状是两个输入张量形状在逐个维度上的最大值。
在任何一个维度上,如果一个张量的大小是 1,另一个张量的大小大于 1,那么这个大小为 1 的张量在该维度上表现得像是被复制了一样。
其他
隐式类型转换
布尔张量与浮点数、整数运算时自动转换为 0 和 1。
整数和浮点数运算时,结果为浮点数。不同精度浮点数运算时,结果为更高精度。
设备
训练过程中模型和数据必须在同一个设备上,否则会报错。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)